tl;dr Streaming context to an LLM as it arrives -- rather than waiting for complete retrieval -- reduces latency dramatically. But prior systems only handle one request at a time. Stream2LLM extends vLLM with concurrent streaming support, introducing scheduling policies that manage memory contention and dynamic input changes across concurrent requests. Evaluated on real-world web crawling and vector search traces, it achieves up to 11x TTFT improvement while maintaining throughput parity.
A user asks a question. Behind the scenes, a web crawler fetches pages to build context over about 10 seconds, with each page arriving roughly 700 milliseconds apart. Without streaming, the user stares at a blank screen the entire time – because the model cannot start until every page has arrived. With streaming, the model starts reading the first page while the rest are still being fetched. The first word appears in under a second.
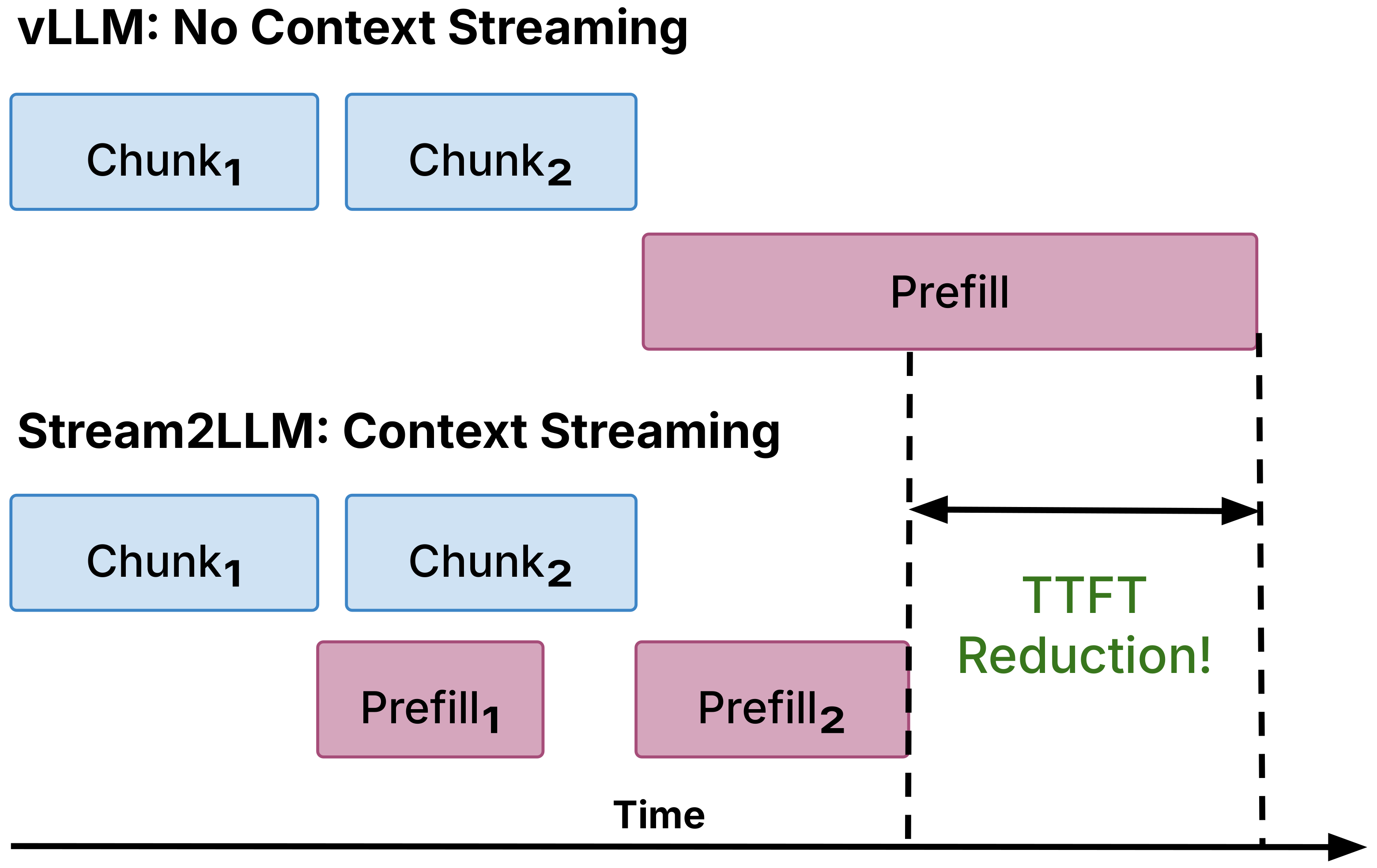
Context streaming overlaps retrieval with prefill, reducing TTFT by beginning inference as chunks arrive.
For a single request, streaming context is straightforward and effective.
Now serve four requests at once. Each is streaming context at a different rate. Each holds KV cache blocks in GPU memory for its growing input. Memory fills up. The scheduler must decide: which request gets evicted? Should its cache be discarded or swapped to CPU? And what happens when a request’s input changes mid-flight because the search algorithm found better documents?
Prior streaming systems do not answer these questions – they evaluate single-request scenarios only. Stream2LLM extends vLLM to handle concurrent streaming, delivering up to 11x faster time-to-first-token (TTFT) while maintaining throughput parity. But there is a catch: naive streaming under memory pressure makes tail latency 5x worse than not streaming at all. Getting the scheduler right is the difference between an 11x win and a 5x regression.
Why Memory and Scheduling Matter
LLM inference has two phases. The prefill phase processes all input tokens in parallel, storing a key vector and value vector for every input token in GPU memory – the KV cache. The decode phase generates tokens one at a time, attending to the full cache at each step.
The cache is expensive. For Llama-3.1-8B with a 32K-token input, it is 4 GB per request in FP16. Serve four concurrent requests and you already have 16 GB of KV cache alone. Scale retrieval time further and memory runs out given the total requests kv state resident in given window of time. When it does, the inference system must evict requests: either discard their cache (recomputation) or move it to CPU (swapping). Both cost time.
Traditional inference waits for all documents before starting prefill. Time-to-first-token is retrieval time plus prefill time, and retrieval dominates – often seconds. Streaming eliminates this wait by feeding documents to the model as they arrive, but existing solutions only handle one request at a time. None address what happens when many requests stream simultaneously.
Two Kinds of Streaming
The complication is that context retrieval doesn’t follow a single pattern. There are two, and they break the KV cache in different ways:
- Append-mode (web crawlers): Documents arrive sequentially and extend the input.
[c1, q]becomes[c1, c2, q]. The cached prefix stays valid, so only the new tokens need processing. Favors swapping to preserve reusable cache. - Update-mode (vector search): The search algorithm refines its results, replacing documents.
[c1, c3, q]becomes[c1, c2, q]– the cached KV pairs forc3are now wrong. The longest common prefix (LCP) between old and new inputs determines how much cache survives. Favors recomputation to avoid retaining soon-invalid data.
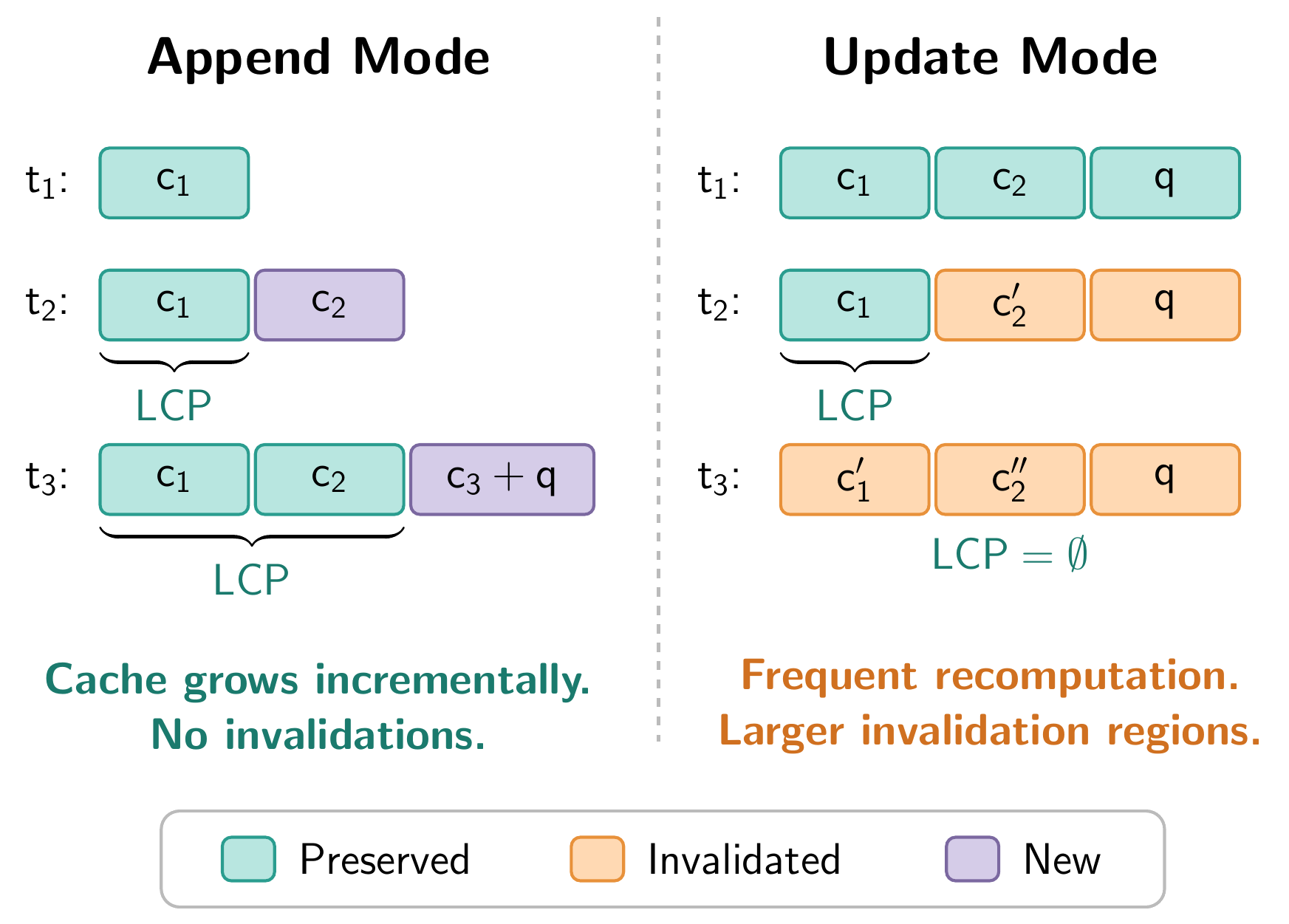
Longest Common Prefix (LCP) invalidation for append-mode and update-mode streaming. Append mode preserves the full prefix; update mode may invalidate significant portions of the KV cache.
The figure above shows the difference concretely. Each row represents the token sequence at a point in time, with blocks showing which KV cache entries survive across updates. In append mode (left), the full prefix is preserved every time a new chunk arrives – the cache grows monotonically and nothing is wasted. In update mode (right), replacing a document in the middle invalidates everything after the longest common prefix. The marked blocks are cached KV pairs that must be discarded because the tokens they correspond to no longer exist in the new input.
A scheduler that treats these uniformly will either waste computation or serve stale cache. Stream2LLM handles both.
A Decoupled Scheduler
Stream2LLM splits the scheduling problem into two independent decisions. It targets the prefill instance in a disaggregated architecture (where prefill and decode run on separate GPU pools). TTFT and throughput are the relevant metrics; decode latency is handled by a separate instance.
The scheduler must answer two questions: which request gets the GPU next, and where do the evicted blocks go? Coupling these decisions makes both worse – fixed eviction rules prevent scheduling algorithms from expressing their priorities.
Two-Phase Scheduling
Stream2LLM separates these concerns into two phases:
Phase 1: Decide who matters most. Rank all unfinished requests by priority and check which ones can fit within the current token budget and GPU block capacity. No memory is allocated – this phase only produces an ordered list.
Phase 2: Make room. Attempt to allocate GPU blocks for the selected requests. If allocation fails, evict the lowest-priority request and use cost-based decisions to choose between recomputation and swapping.
The separation means you can swap in a different scheduling policy without touching the eviction logic, and vice versa.
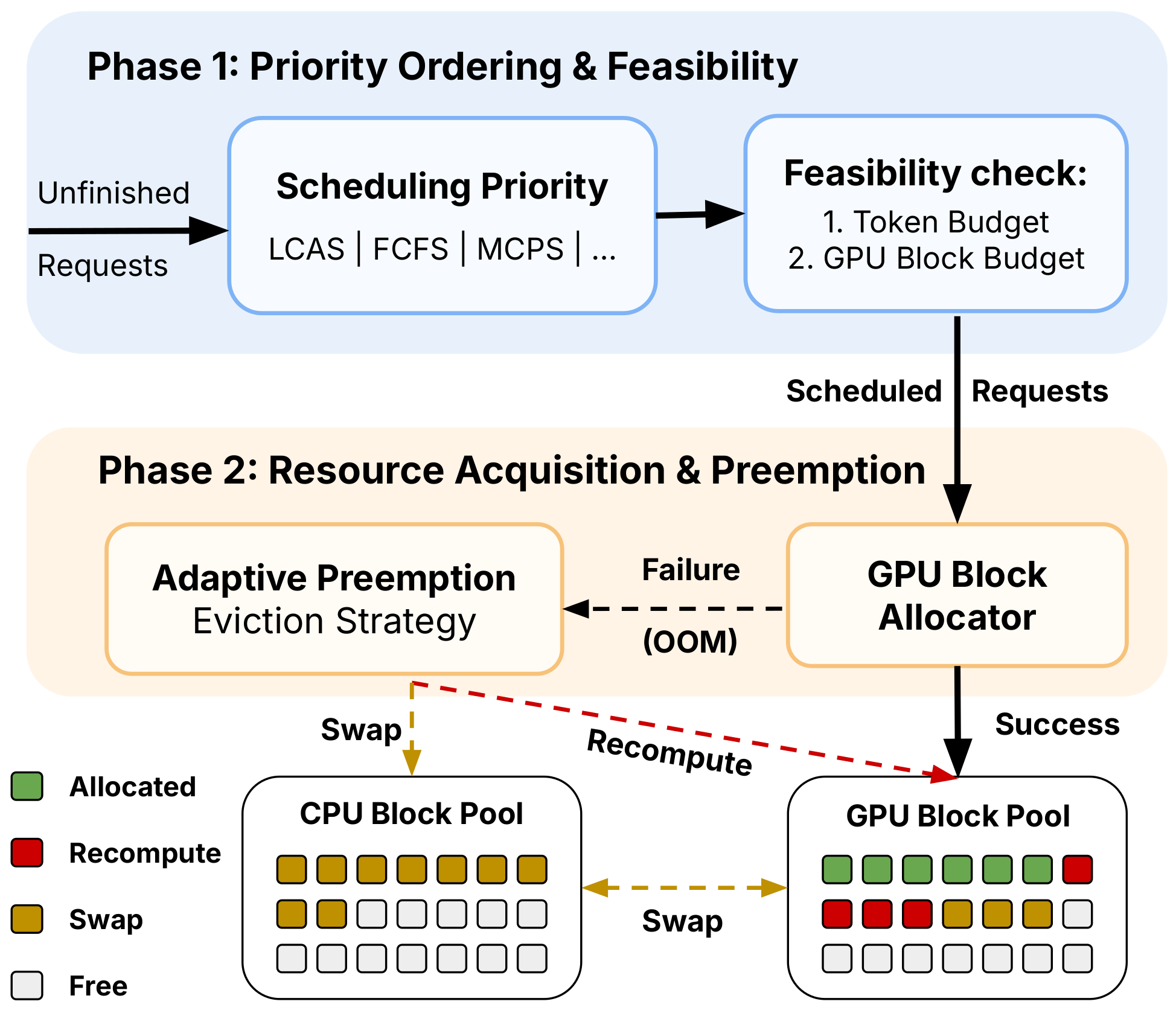
Stream2LLM system design showing the two-phase scheduling architecture with streaming input support.
On the left, multiple clients stream context chunks into the system concurrently – each request’s input grows over time as retrieval progresses. These streaming inputs feed into the two-phase scheduler at the center.
In Phase 1, the scheduler ranks all active requests by the chosen scheduling policy (FCFS, LCAS, or MCPS) and determines which ones fit within the current token budget and available GPU block capacity. No memory is allocated yet – this phase produces only a priority-ordered list of requests to schedule.
In Phase 2, the scheduler attempts to allocate GPU memory blocks for the selected requests. When the KV cache pool is full, it evicts the lowest-priority request. The eviction decision – recompute from scratch or swap blocks to CPU – is made by the cost-based module on the right, which consults hardware-profiled latency models to pick the cheaper option. Evicted requests re-enter the waiting queue and are reconsidered in the next scheduling cycle.
The key insight is that the arrows between Phase 1 and Phase 2 go in one direction: the priority policy never needs to know about eviction mechanics, and the eviction module never needs to know about scheduling priorities. This decoupling is what makes it possible to swap in different policies without rewriting the memory management logic.
LCP-Based Cache Invalidation
A unique challenge for streaming inputs is that the token sequence itself changes dynamically. When a new chunk arrives, the scheduler must decide which cached KV blocks remain valid. Naive full-invalidation wastes memory and forces expensive recomputation; reusing blocks without verification risks incorrect output based on stale cache.
Stream2LLM computes the longest common prefix (LCP) between the old and new input token sequences – the portion that has not changed. Only KV cache blocks beyond this prefix are invalidated, preserving blocks for unchanged tokens.
For example, suppose a request previously computed KV cache for tokens [c1, c2, q, output1, output2], and an input update replaces this with [c1, c2', q, output1, output2] where c2' != c2. The LCP is [c1] (length 1). The scheduler invalidates cache blocks for tokens 1 onward while preserving the KV cache for token 0.
The LCP approach is optimal when input updates append new chunks or replace suffix tokens – typical in context retrieval.
Cost-Based Preemption
When GPU memory is exhausted, Stream2LLM chooses between recomputing tokens and swapping KV blocks to CPU. Both have hardware-specific costs – recomputing 30K tokens takes ~100ms on H200 but ~1000ms on A40 – so the scheduler profiles both offline on each target GPU and picks the cheaper option at eviction time.
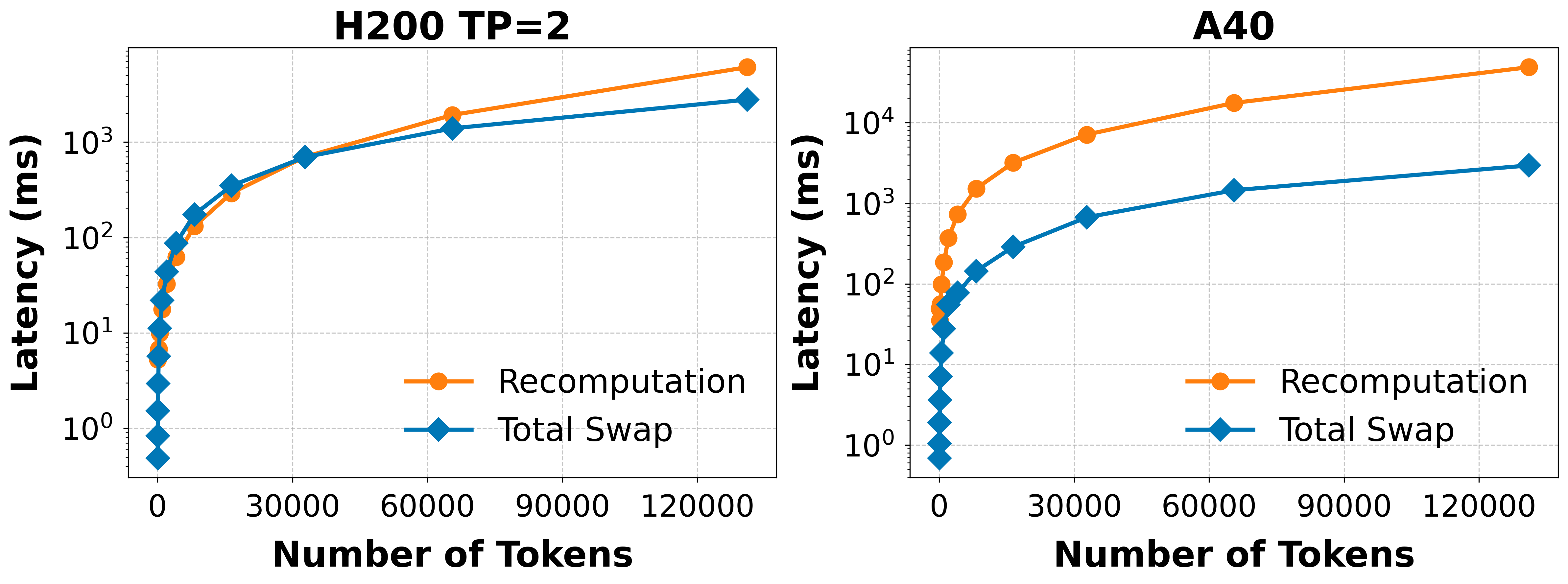
Performance models for recomputation vs. total swap latency costs across token counts on H200 and A40. The scheduler selects the lower-cost strategy at preemption time.
Scheduling Policies
A note on labels used throughout the rest of the post: vLLM-NS is the unmodified vLLM baseline with no streaming, vLLM-S is vLLM with streaming but no custom scheduling, and the Stream2LLM-* variants are streaming combined with each of the custom scheduling policies introduced below.
Stream2LLM implements four scheduling algorithms:
| Scheduling Policy | Append Mode | Update Mode | Key Behavior |
|---|---|---|---|
| vLLM-S (default streaming) | Poor | Poor | Arrival-time ordering; ignores when chunks arrive. Catastrophic under memory pressure |
| Stream2LLM-FCFS (First-Come-First-Served) | Excellent | Excellent | Ensures requests with complete context get processed before partially-streamed ones, preventing starvation |
| Stream2LLM-MCPS (Most Chunks Processed) | Poor | Poor | Prioritizes requests with most tokens computed; priority collapses when updates reset progress |
| Stream2LLM-LCAS (Last Chunk Arrival) | Excellent | Good | Prioritizes most recent chunk arrival; best general-purpose choice |
Stream2LLM scheduling policies and their behavior under append-mode and update-mode streaming.
The core principle is to prioritize requests that just received fresh context. LCAS does this directly and handles both modes well. FCFS achieves the strongest results under memory pressure by cleanly separating complete from partial requests. MCPS looks reasonable in theory but fails in practice. It prioritizes by absolute computed token count – requests with the most tokens already processed go first. In append mode, a request that just received a fresh chunk has fewer computed tokens than one that has been processing longer, so fresh content sits idle while nearly-complete requests monopolize the GPU. Under memory pressure, these low-priority fresh-content requests are also the first to be evicted. In update mode it is worse: invalidation resets the computed count to near zero, dropping the request to lowest priority entirely.
Does It Work?
There are no public streaming workload traces. We built two – one for each retrieval pattern – and replayed them at varying queries per second (QPS).
| Metric | Vector Search (Update) | Crawler (Append) |
|---|---|---|
| Queries | 500 | 4,322 |
| Mean tokens/query | 13K | 9.1K |
| P50 tokens/query | 10K | 5.8K |
| P95 tokens/query | 31K | 28.9K |
| Mean retrieval latency | 4.5s | 9.9s |
Workload statistics for the vector search (update mode) and crawler (append mode) traces.
The update-mode trace comes from a disk-based approximate nearest neighbor search (ANNS) – a form of vector search – over a 372 GB corpus. The append-mode trace comes from a web crawler fetching pages up to depth 2. Both are high-latency, I/O-bound retrieval scenarios.
The workloads differ sharply in chunk arrival patterns:
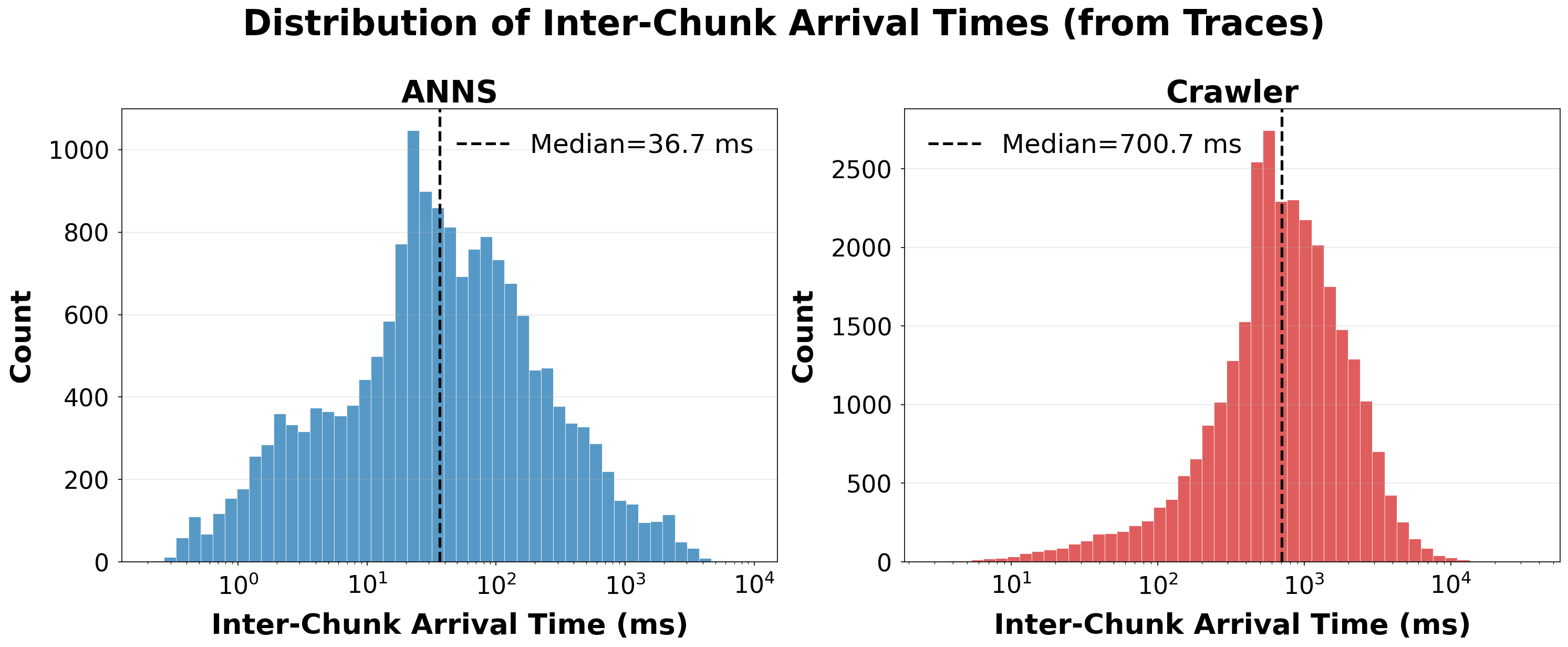
Distribution of inter-chunk arrival times. Vector search chunks arrive with a median of 36.7ms; crawler chunks arrive with a median of 700.7ms with significantly higher variability.
Hardware: NVIDIA H200 (141GB) and H100 (80GB) GPUs with Llama-3.1-8B-Instruct, tensor parallelism of 2, and 80% GPU memory utilization target. All experiments target the prefill instance.
Latency: Up to 11x Faster
Each panel below shows what fraction of requests exceed a given TTFT – curves further left mean lower latency. The y-axis is log-scale, so differences at the bottom of each plot reflect tail behavior.
TTFT CCDF across load levels for the crawler (top) and vector search (bottom) workloads on H200. Streaming achieves up to 10.8-11.0x faster median latencies on the crawler workload and 2.49-2.63x P95 speedups on the vector search workload.
Crawler workload (append mode): Streaming improves TTFT at every load level. The gap widens with load: $\sim 4\times$ faster at low QPS, $\sim 11\times$ at high QPS. Scheduler choice matters only when page arrival rate approaches the prefill rate – at QPS 4, FCFS delivers $3.2\times$ P95 speedup over vLLM-S while MCPS degrades to $0.7\times$, deprioritizing requests with fresh content.
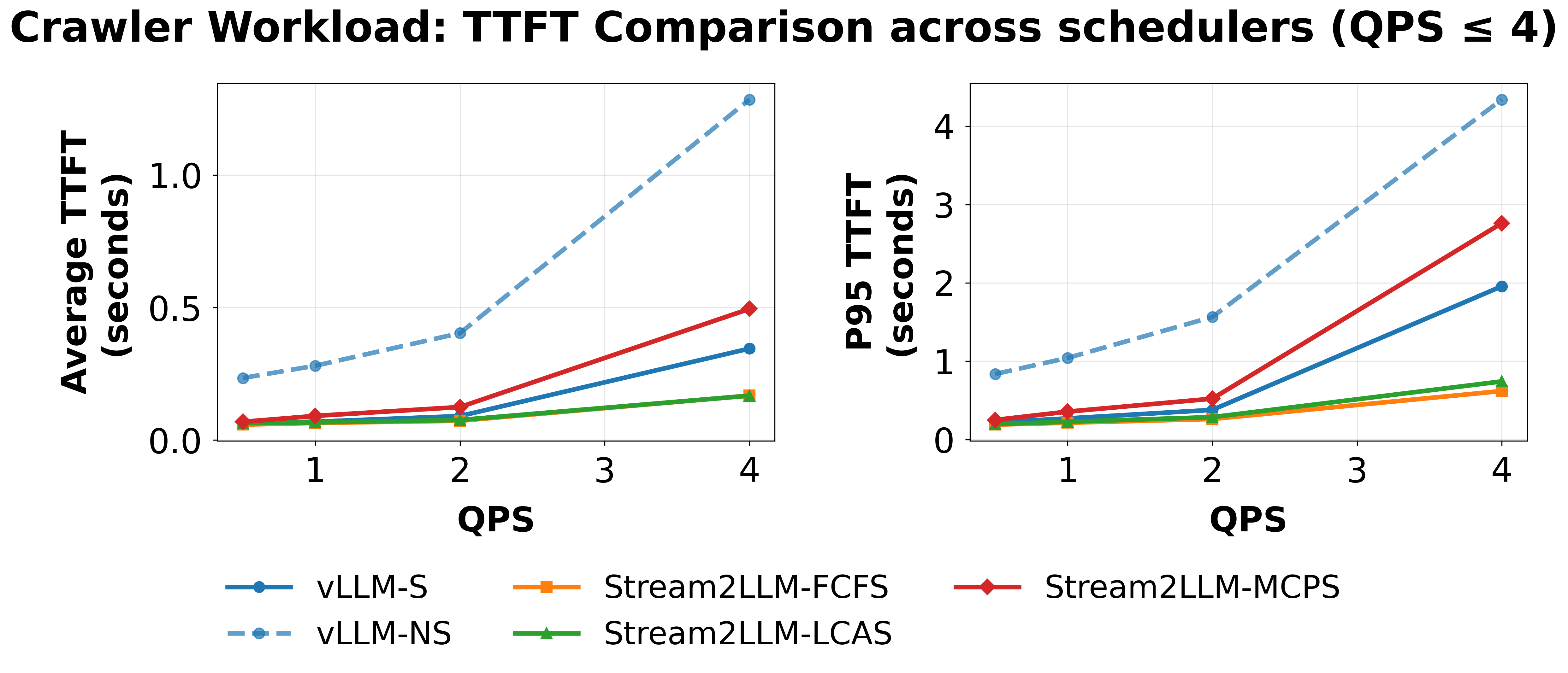
Crawler workload: TTFT (average and P95) vs. QPS on H200 across all schedulers.
Vector search workload (update mode): At low load, all streaming schedulers converge near $2.5\times$ P95 speedup. At QPS 2, differentiation emerges: FCFS achieves $2.3\times$, LCAS $1.8\times$, and MCPS drops to $1.5\times$. Despite significant cache invalidation, streaming still delivers $\sim 2\times$ faster TTFT than non-streaming.
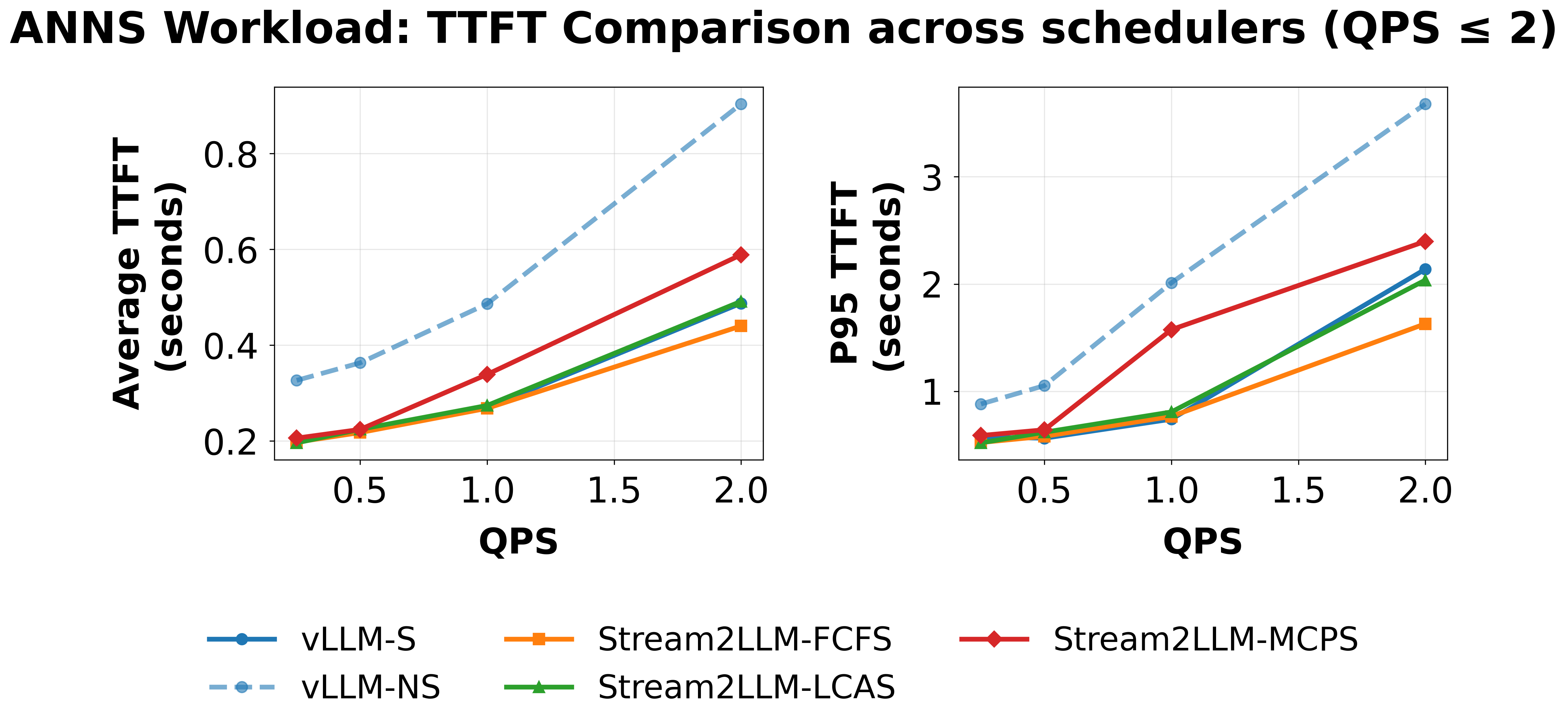
vector search workload: TTFT (average and P95) vs. QPS on H200 across all schedulers.
Throughput Is Unaffected
The latency gains raise a natural question: does streaming create overhead that slows total job completion? No. Trace completion times are near-identical across all methods (within ~1%).
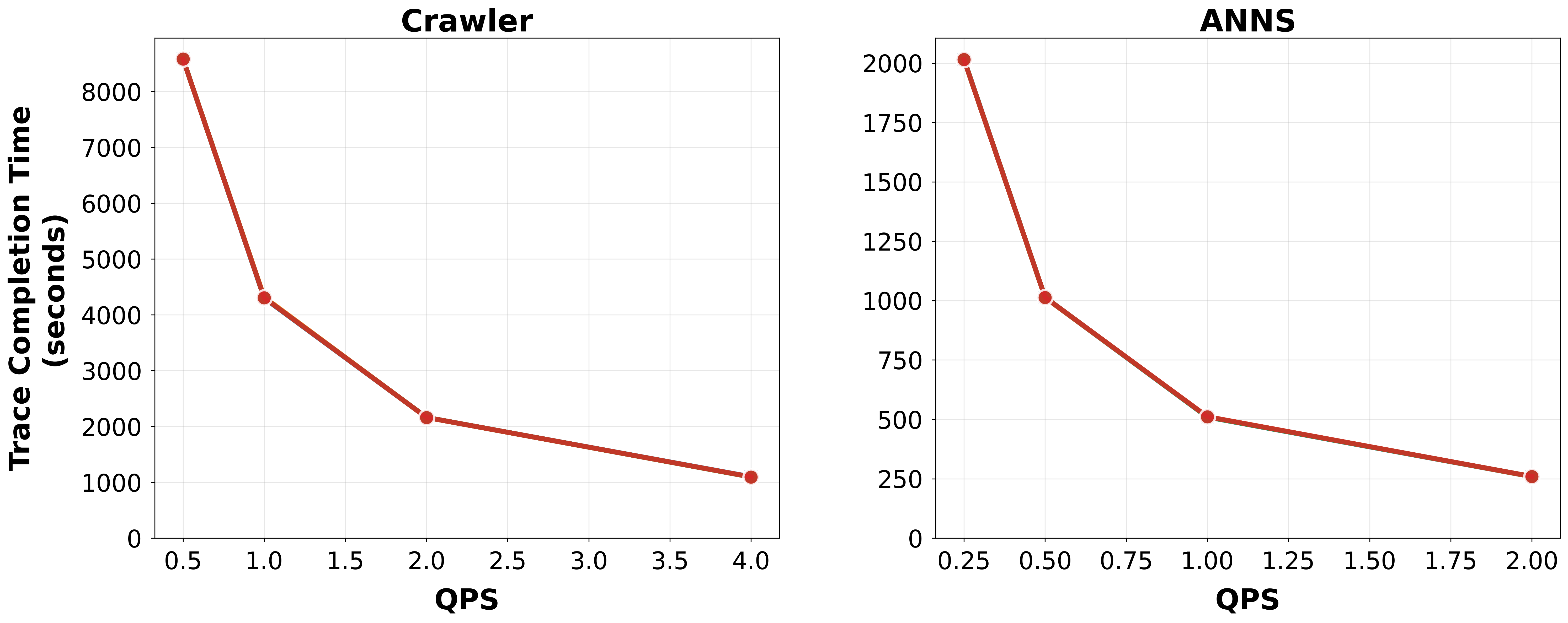
Trace completion time across QPS levels for both workloads. All scheduler variants achieve near-identical completion times, confirming throughput parity.
When Memory Runs Out
The H200’s 141 GB is generous enough that preemption never triggers at normal loads. To force the issue, we increased chunk delays ($10\times$ for crawler, $30\times$ for vector search), saturating the KV cache pool. This is where scheduler choice becomes critical. The numbers to watch are the P99 columns – that is where naive streaming collapses.
Speedup values are relative to the non-streaming baseline (first row). Values below 1.0x mean streaming is slower than not streaming.
| Scheduler | Recompute P50 | Swap P50 | Cost-Based P50 | Recompute P99 | Swap P99 | Cost-Based P99 |
|---|---|---|---|---|---|---|
| vLLM-NS | 0.64s | 0.64s | 0.64s | 8.97s | 8.97s | 8.97s |
| vLLM-S | 8.59x | 7.29x | 8.25x | 0.78x | 0.66x | 0.71x |
| Stream2LLM-FCFS | 8.77x | 7.78x | 8.30x | 10.03x | 6.69x | 8.62x |
| Stream2LLM-LCAS | 8.61x | 7.32x | 7.82x | 9.23x | 4.80x | 9.14x |
| Stream2LLM-MCPS | 5.92x | 3.86x | 4.96x | 0.73x | 0.48x | 0.77x |
Crawler workload (append mode, 4.0 QPS, 10x delays): TTFT speedups at P50 and P99 relative to the non-streaming baseline.
| Scheduler | Recompute P50 | Swap P50 | Cost-Based P50 | Recompute P99 | Swap P99 | Cost-Based P99 |
|---|---|---|---|---|---|---|
| vLLM-NS | 0.72s | 0.72s | 0.72s | 6.56s | 6.56s | 6.56s |
| vLLM-S | 2.53x | 2.26x | 2.63x | 0.19x | 0.18x | 0.19x |
| Stream2LLM-FCFS | 2.70x | 2.37x | 2.70x | 1.84x | 1.26x | 2.04x |
| Stream2LLM-LCAS | 2.38x | 1.62x | 2.44x | 1.79x | 0.97x | 1.79x |
| Stream2LLM-MCPS | 2.20x | 1.47x | 2.23x | 0.19x | 0.22x | 0.19x |
Vector search workload (update mode, 2.0 QPS, 30x delays): TTFT speedups at P50 and P99 relative to the non-streaming baseline.
Two key findings:
-
vLLM-S collapses under memory pressure. At P99, it degrades to $0.71\times$ (crawler) and $0.19\times$ (vector search) – streaming without a proper scheduling policy is actively harmful under contention.
-
Eviction strategy is hardware-dependent. Recompute-only FCFS reaches $10.03\times$ at P99 on the crawler workload but swap-only drops to $6.69\times$. The cost-based approach adapts to the hardware, achieving $8.62\times$ (FCFS) and $9.14\times$ (LCAS) by picking the cheaper option at each eviction.
What This Means
If you serve LLM requests backed by retrieval – web crawling, vector search, tool calls – you are paying a latency tax every time you wait for complete context before starting prefill.
Three takeaways:
- Start prefilling on partial context. Median TTFT improves 4-11x for append-mode workloads. If your retrieval takes more than a second, this dominates every other optimization you could make.
- Do not stream without a proper scheduling policy. vLLM-S under memory pressure produces P99 latencies 5x worse than not streaming. Use FCFS or LCAS.
- Profile your eviction costs. Whether to recompute or swap depends on your GPU. A five-minute offline profile determines the right strategy.
The system, the traces, and the evaluation code are all public.
Paper: Stream2LLM (MLSys 2026)
Code: github.com/rajveerb/stream2llm